2024年AAAI国际人工智能顶级会议(AAAI Conference on Artificial Intelligence, AAAI)录用结果公布,本实验室在光流估计、图形快速渲染、模型优化和伪造检测领域的研究成果受到认可,共有四篇论文被会议录用。这些论文分别是《SAMFlow: Eliminating Any Fragmentation in Optical Flow with Segment Anything Model》、《Low-latency Space-time Supersampling for Real-time Rendering》、《Context-Aware Iteration Policy Network for Efficient Optical Flow Estimation》和《MGQFormer: Mask-Guided Query-based Transformer for Image Manipulation Localization》。
AAAI是国际人工智能的最顶级盛会之一,也是中国计算机学会推荐的人工智能领域的A类国际学术会议。2024年,AAAI主办地为加拿大温哥华,投稿量9862篇,录用文章2342篇,录用率为23.75%。
论文一:

光流估计是计算机视觉中的一项基本任务,旨在确定视频帧之间像素的移动。这一过程对许多视频相关应用至关重要,但目前的光流估计方法面临着两个主要挑战:1. 标记数据集的稀缺:在现实场景中获得像素级运动数据非常困难,这导致人们依赖人工合成的数据集,缺乏自然场景的多样性和真实性。2. 缺乏高级理解:传统的光流模型主要关注局部的低层次线索,未能对物体的整体性有一定感知能力,经常导致对同一对象的流预测出现“碎片化”,如图1(a)中第一行结果。
本文观察到,近期的Segment Anything Model恰好具备了解决这两个挑战的可能性,因此考虑将其结合至光流估计方法之中。进一步地,为了克服光流估计与分割任务领域知识不匹配的问题,本文提出了一种双重适应方案,如图 2。 这一方案包含两个模块:1. 上下文融合模块(CFM):该模块将SAM编码器与光流任务特定编码器融合,旨在提取特征时兼顾两者。2. 上下文适应模块(CAM):该模块通过Two-Way Attention(TWA)块和可学习的任务特定嵌入(LTSE),将更多任务特定知识注入融合特征中,以适应光流估计的特定要求。通过在Sintel和KITTI-2015数据集上进行的测试,本文证明了方法的有效性和优越性,如图3。可视化的结果(图1)也证明了本文方法对碎片化的消除能力。同时,本文也在在线的光流估计benchmark网站上进行了更加严格的测试,并在Sintel clean pass榜单上取得了在两帧方法中排名第一的成绩。

图1:(a)碎片化案例与本文模型无碎片化预测结果的对比。(b) 特征相关性可视化对比。
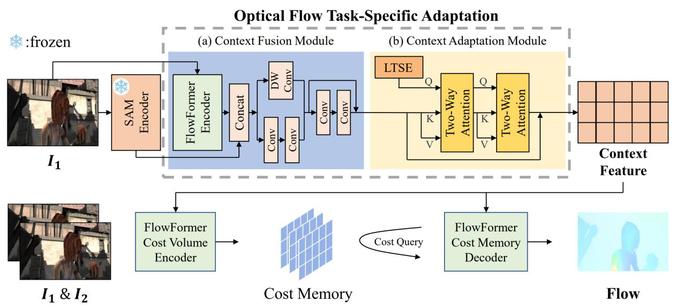
图2:模型框架
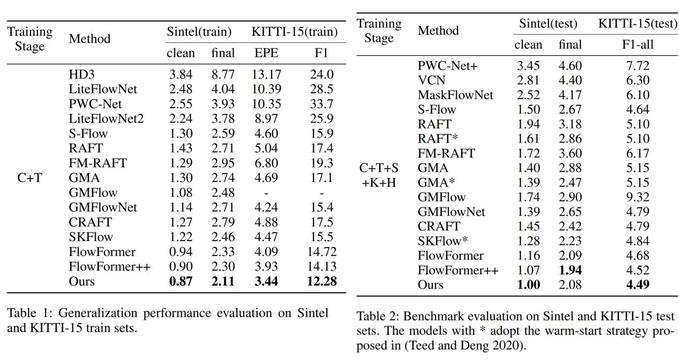
图3:实验结果对比
论文二:

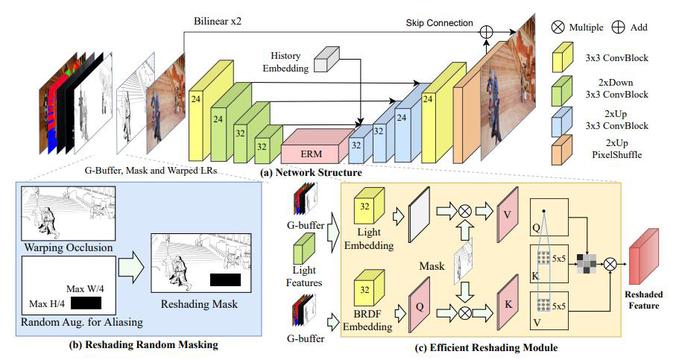
图4:提出方法的网络结构

图5:实验结果对比
随着实时渲染技术的崛起和显示设备的发展,对于能够提供高分辨率内容的高帧率后处理方法的需求日益增长。现有技术常常因为帧超采样和外推处理的脱节而遭受质量和延迟问题。在本论文中,我们认识到了帧超采样和外推之间的共享的上下文和处理机制,并提出了一个新颖的框架,即时空超采样(Space-time Supersampling,STSS)。通过将它们整合到一个统一的框架中,STSS能够在降低延迟的同时提升整体质量(图4)。为了实现一个高效的架构,我们将混叠和扭曲孔洞统一视为重着色区域,并提出了两个关键组件来补偿这些区域,分别是随机重着色掩蔽(Random Reshading Masking,RRM)和高效重着色模块(Efficient Reshading Module,ERM)。广泛的实验表明,我们的方法与最先进方法相比,达到了更优越的视觉保真度(图5)。值得注意的是,这种性能仅在4ms内就能实现,相较于需要17ms的传统两阶段管道,节省了高达75%的时间。
论文三:


图6:模型框架
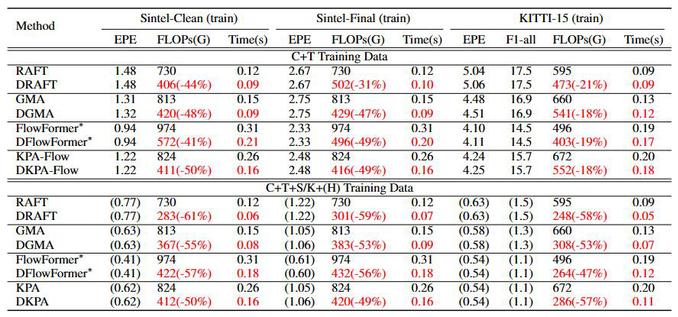
图7:实验结果对比
现有的循环光流估计网络在计算上代价高昂,因为它们使用固定的且大量迭代次数来更新每个样本的光流。一个高效的网络应该在光流改进有限时跳过迭代。在本文中,我们提出了一个用于高效光流估计的上下文感知迭代策略网络(图6),该网络确定每个样本的最佳迭代次数。具体来说,该策略网络通过学习上下文信息来实现判断光流改进是否微小。一方面,我们使用迭代嵌入和历史隐藏单元来传达光流是如何从之前的迭代中变化的。另一方面,我们使用增量损失使策略网络隐式感知后续迭代中光流改进的幅度。此外,我们动态网络中的计算复杂性是可控的,允许我们用单一训练模型满足各种资源偏好。我们的策略网络可以轻松集成到最先进的光流网络中。广泛的实验表明,我们的方法在减少约40%/20%的FLOPs的同时保持了对Sintel/KITTI数据集的性能(图7)。
论文四:

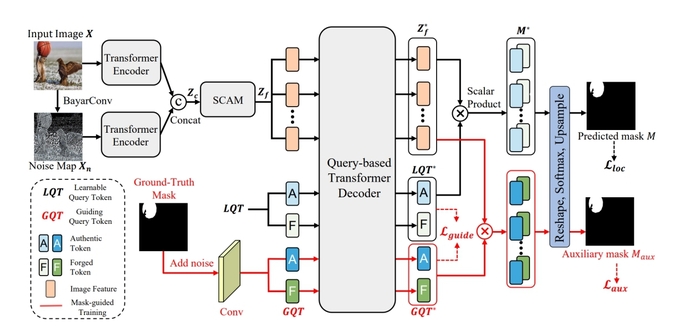
图8:提出的方法结构

图9实验结果对比
基于深度学习的模型在图像篡改定位方面取得了巨大的进展,其目标是区分被篡改和真实区域。然而,这些模型在训练效率上存在问题。这是因为它们主要通过交叉熵损失使用真值掩码,该损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节。为了解决这个问题,我们提出了一种掩码引导的基于查询的Transformer(MGQFormer),它使用真值掩码来引导可学习的查询令牌(LQT)以识别伪造区域(图8)。具体而言,我们提取真值掩码的特征嵌入作为引导查询令牌(GQT),并将GQT和LQT输入到MGQFormer中以分别估计伪造区域。然后,我们通过引入掩码引导损失来使MGQFormer学习真值掩码标签中的位置和形状信息,以减小GQT和LQT之间的特征距离。我们还观察到这种掩码引导训练策略对MGQFormer训练的收敛速度具有显著影响。在多个基准测试上进行的大量实验证明,我们的方法明显优于最先进的方法(图9)。